大模型量化系列(一):LLM.int8() — 重新定义量化领域的问题空间
论文: LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
作者: Tim Dettmers, Mike Lewis, Younes Belkada, Luke Zettlemoyer
发表: NeurIPS 2022 | arXiv:2208.07339
一句话总结: LLM.int8() 首次揭示了 LLM 中的 outlier(emergent feature)现象,成为此后大模型量化研究的重要出发点。
一、为什么传统量化在大模型上会崩溃
在讨论 LLM.int8() 之前,我们需要先理解一个看起来理所当然、实则并不显然的问题:为什么简单的 INT8 量化,在小模型上跑得飞起,一到 6.7B 以上的大模型就全面崩溃?
要回答这个问题,得从量化最基础的两套方法讲起。
1. Absmax 量化:最简单,但也最脆弱
Absmax(绝对最大值量化)是工程中最常用的方案。核心思想一句话:找到整个张量的绝对最大值,等比例缩放到 INT8 的 [-127, 127] 范围。
量化公式:
缩放因子:
反量化则是:
优点: 计算简单,只需一个缩放因子,乘法就能还原。实际部署中最常用。
缺点有两个:
- 一个异常值就能”撑大”缩放因子,把正常值的信息压缩到几乎为零
- 如果数据分布不以零为中心(比如 ReLU 的输出全是正数),
[-127, 0]这半段范围就完全浪费了——相当于你画地图时把整张纸的左半边留空了
2. Zeropoint 量化:更精确,但更贵
Zeropoint 量化(非对称量化)在 Absmax 的基础上引入了零点偏移,专门解决”数据不以零为中心”的问题。它做了两件事:
- 用最大值和最小值的差(而不是绝对最大值)来决定动态范围
- 加一个零点偏移
,让 INT8 的 0 对应到 FP16 数据的实际”中心”
优点: 通过仿射变换铺满 INT8 的全部范围,对非对称分布更友好。
缺点更致命: 矩阵乘法时需要处理零点偏移。在没有专用指令的 GPU/TPU 上,一个乘法被展开为四项:
计算开销显著增大。所以虽然理论上更精确,实际工程中反而不如 Absmax 常用。
3. 量化粒度:从 Tensor-wise 到 Row-wise
上面两种方法默认是 tensor-wise 的——整个张量用一个缩放因子。
一个自然的改进是 row-wise 量化:每行用独立的缩放因子,把异常值的影响限制在单行内。
| 粒度 | 做法 | 优点 | 局限 |
|---|---|---|---|
| Tensor-wise | 整个张量一个缩放因子 | 最简单 | 一个异常值毁掉全局 |
| Row-wise | 每行独立缩放因子 | 隔离异常值影响 | 粒度仍不够细 |
到这里,你可能在想:继续把粒度调细不就行了? 问题在于,当异常维度本身就在矩阵乘法中跨行传播时,row-wise 也兜不住了。
核心结论:无论怎么调粒度,只要有一个异常维度,传统量化就会失败。 而 LLM.int8() 的发现,正是解释了这个”异常维度”究竟是什么、为什么在大模型上无法回避。
二、LLM.int8() 的核心发现
Outlier Features:模型大了以后,会出现什么
论文最重要的发现不是一个量化技巧,而是一个现象:
当模型规模超过约 6.7B 参数时,Transformer 的隐藏状态中会出现极少数”异常特征”(outlier features)。
这些异常特征有三个令人不安的特点:
- 数量极少: 在上千个隐藏维度中,只有大约 6 个维度 出现异常——占比不到 0.1%
- 幅度极大: 这些异常值的 magnitude 比普通值大 100 倍以上
- 高度规律: 它们在不同输入、不同层中稳定出现在相同的维度上
“稳定出现在相同的维度”这一点最为关键。它说明异常不是随机的噪声,而是模型结构本身的固有属性——某种”涌现”出来的行为。这也解释了为什么传统的随机 dropout、正则化等手段对这个问题无能为力。
这意味着什么?如果你用传统的标量量化,缩放因子
一个有趣的对比
Outlier Features 的发现,本质上和物理学中的”涌现”概念异曲同工:单个粒子遵循简单的规则,但大量粒子聚集时会突然表现出全新的宏观行为。LLM.int8() 首次在大模型中发现并定量描述了这种”涌现式异常”——它不是在解释模型的能力,而是在解释模型的脆弱性。
这个发现比任何量化技巧都重要。因为它把问题从”怎么量化得更好”重新定义为”怎么处理这些异常值”——后续所有 LLM 量化工作(SmoothQuant、AWQ、GPTQ)都在回答同一个问题。
三、LLM.int8() 的解决方案
理解了问题,解决方案的逻辑就清晰了。LLM.int8() 做了两件事:
第一步:向量量化(Vector-wise Quantization)
在 row-wise 的基础上再推一步:不再按行或按列独立量化,而是把矩阵乘法看作一系列独立的内积,每个内积都有自己的缩放因子。
- 对激活矩阵
的每一行计算独立的缩放因子 - 对权重矩阵
的每一列计算独立的缩放因子
反量化时,对每个输出元素只需将对应的行、列缩放因子相乘:
其中
相比 row-wise,vector-wise 的粒度细得多——它让每个内积(即输出矩阵的每个元素)都有最优的缩放组合。对于绝大多数”正常”数据,这一步已经足够好了。
第二步:混合精度分解(Mixed-Precision Decomposition)
但向量量化仍然搞不定那 6 个异常维度。LLM.int8() 的做法粗暴而有效:把它们单独拎出来,用 FP16 精确计算。
具体流程:
- 识别异常维度: 设定一个阈值(如 6.0),找出 magnitude 超过阈值的特征维度
- 拆分矩阵: 将输入按维度拆成两部分——异常部分和正常部分
- 双路计算:
- 异常维度(约 0.1%)→ FP16 矩阵乘法
- 正常维度(约 99.9%)→ INT8 矩阵乘法
- 合并结果: 将两路结果相加,得到最终的 FP16 输出
用公式表达就是:
完整架构:一图看懂
下面结合原论文的流程图,完整梳理数据流向:
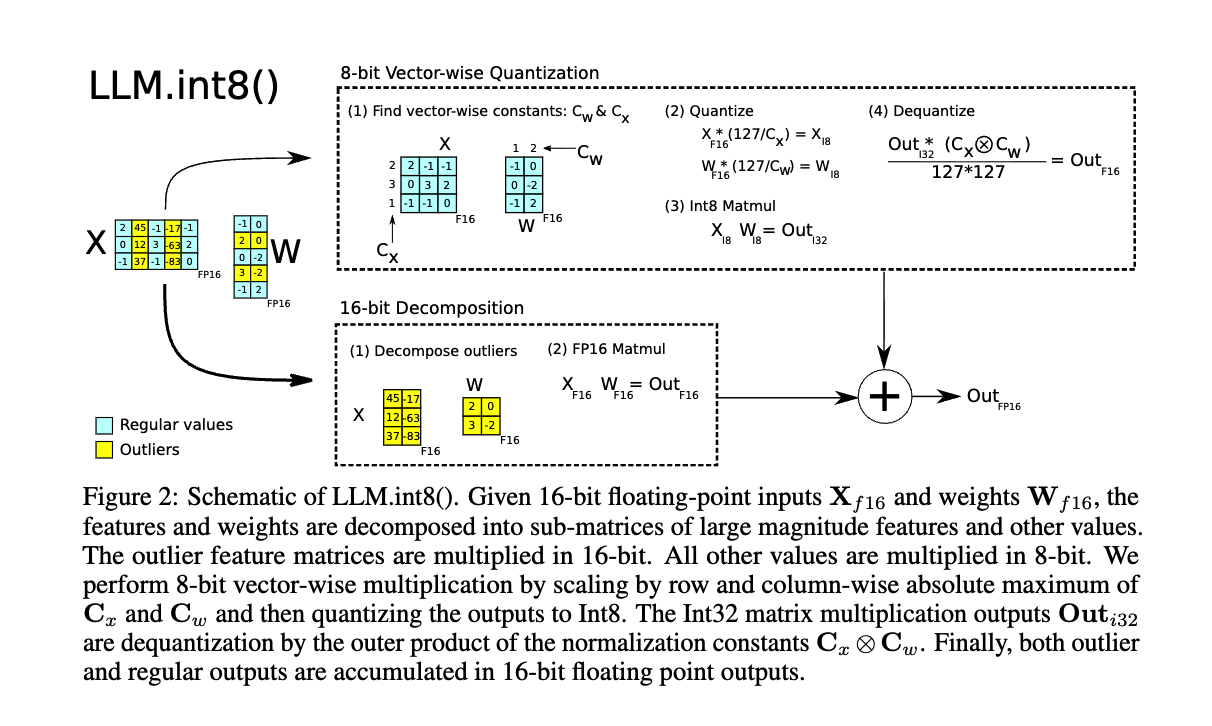
流程图分为两条并行路径,最终相加得到 FP16 输出。逐部分拆解:
上半部分:8-bit Vector-wise Quantization(虚线框内)
处理常规值(浅蓝色方块) 的主路径,包含 4 个步骤:
Step (1) — 查找向量级缩放常量
- 对激活矩阵
的每一行求绝对最大值,得到行缩放因子向量 。例如图中的 第一行为 2,是因为该行最大值是 - 对权重矩阵
的每一列求绝对最大值,得到列缩放因子向量
Step (2) — 量化
- 激活值:
—— 每行除以自己的缩放因子,乘 127,取整到 [-127, 127]的整数 - 权重值:
—— 每列除以自己的缩放因子,同理取整
Step (3) — INT8 矩阵乘法
- 用量化后的矩阵做乘法:
- INT8 × INT8 的乘积会溢出 8-bit,所以累积结果存为 INT32
Step (4) — 反量化
- 用外积
逐元素缩放 INT32 输出:
- 除以
是因为量化时乘了两次 127,反量化时需要除回来
下半部分:16-bit Decomposition(虚线框内)
处理异常值(黄色方块) 的路径:
Step (1) — 分解异常值
- 从激活矩阵
中挑出 magnitude 超过阈值的列(即异常维度)及其对应的权重列 - 例图中
的第 1 列(值 45, 12, 37)和第 3 列(值 17, 63, 83)被识别为异常列 - 这些值远超同矩阵中其他元素,无法用 INT8 表示
Step (2) — FP16 矩阵乘法
- 异常部分直接用 FP16 计算:
- 虽然这部分不能享受量化加速,但因为异常维度占比极小(约 0.1%),额外开销可以忽略
最终融合
两条路径在最下方的加号处汇合:
关键设计洞察:
- INT8 路径承担了 99.9% 的计算量,享受显存减半和计算加速
- FP16 路径只处理极少量异常值,确保精度不损失
- 对外部调用者来说完全透明——就像从未做过量化一样
个人评价:这个方法”不优雅”
说实话,混合精度分解是一个工程妥协,不是理论胜利。它本质上是在说:”这个问题太难了,我们把搞不定的那 0.1% 跳过算了。”
但它解决的是当时最紧迫的问题——在 2022 年,当 OPT-175B 和 BLOOM-176B 这样的模型因为显存问题几乎无法在实验室外被使用时,一个”不优雅但有效”的方案比一个”优雅但做不到”的方案有价值得多。
就像第一个登上珠峰的人——路线不一定是最优的,但证明了一件事:能上去。
四、实验结果与影响
论文在 125M 到 175B 的多个模型上验证:OPT-175B 和 BLOOM-176B 与 FP16 基线相比零精度损失;BLOOM-176B 推理从 8×80GB A100 缩减到 4×80GB A100;超大模型相比 FP16 慢约 15-23%(主要瓶颈在 INT8 Tensor Core 利用率)。作为对比,朴素 INT8 在 6.7B 以上模型直接性能崩塌。
LLM.int8() 快速落地到了工程——作者团队开源了 bitsandbytes 库,通过 Hugging Face 集成后一行代码即可启用,成为历史上第一个让普通开发者在消费级 GPU 上跑 175B 模型的方法。
局限性也很明显:仅支持 NVIDIA GPU(Turing+),无法直接保存和加载 INT8 权重(每次需从 FP16 重新量化),对小模型加速有限。这些局限说明它不是终态。
五、结语:真正的遗产是定义了问题
LLM.int8() 的真正价值不在于方法本身的精巧——混合精度分解本质上是一种工程暴力——而在于它定义了一个正确的问题:怎么处理 outlier features。
后续方法都在回答它留下的问题:SmoothQuant 回答能不能不跳过异常值而是把它们”平滑”掉;GPTQ 回答 weight 能不能压到 4-bit;AWQ 回答 weight 中是否也存在类似 activation 的”关键 1%”。
但这篇要记住的核心就一句话:LLM.int8() 不是大模型量化的终点,而是所有人必须回去引用的那个起点。